부트캠프 과제 구현 중 기록
100만 건의 데이터를 생성해 저장하고, 목록을 조회 하기
목록 조회 시 성능을 개선하기 위한 방법 기록
대용량 데이터 생성 후 저장: https://rvrlo.tistory.com/entry/SpringBootJPA-JDBC-Batch-Insert를-통해-대용량-데이터-저장하기
🔎 과제 분석
저번 글에서 대용량 데이터를 생성하여 테이블에 저장했으니, 이번에는 조회 성능을 개선해보기로 한다.
조회 속도를 개선하기 위해 여러 방법을 고려해보라고 했고, 제일 먼저 떠오른 것은 인덱스를 이용하는 것이었다.
✨ MySQL - Search
- all, index: 테이블 전체 스캔(인덱스x)
- range: 인덱스를 사용한 범위 검색
- fulltext:
MATCH .. AGAINST구문을 사용 - ref, eq_ref, const:
JOIN시 주로 발생
Spring에서 Entity 생성 시 @Table의 indexes속성을 이용해 인덱스를 지정할 수 있다.
@Table(indexes = {@Index(name="index이름", columnList = "지정할 column")}이렇게 인덱스를 지정하면 JPA가 테이블을 만들 때 인덱스를 함께 만들어준다.
인덱싱 기법
- Stop-word parser
공백이나 Tab, 문장 기호, 사용자가 정의한 문자열 검색하는 단어가 정확히 일치해야 한다. - N-gram parser
할당한 토큰의 크기 n만큼 데이터를 인덱스로 파싱
Full text index
텍스트로 구성된 데이터 내용으로 생성된 인덱스
테이블 생성 시 인덱스를 설정하거나, 테이블을 수정하고 인덱스를 추가할 수 있다.
CREATE TABLE "table명"(
...
"column명" TEXT NOT NULL,
FULLTEXT KEY "index이름"("지정할 column")
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;ALTER TABLE "테이블명" ADD FULLTEXT("컬럼명");
검색을 할 때는 MATCH ... AGAINST 를 이용해 검색한다.
SELECT * FROM "테이블명" WHERE MATCH("검색할컬럼명"[, ...]) AGAINST("검색할키워드" "검색모드");
위에 적힌 모드는 Full-Text를 이용해 검색할 때 사용할 유형으로 Natural Language와 Boolean이 있다.
Natural Language Mode
검색 문자열과 목록에 명명된 열 → 해당 행의 텍스트 간 유사성 측정
∴ 검색할 문자열을 단어로 분리
SELECT *
FROM "table명"
WHERE MATCH ("index이름") AGAINST ('찾을 내용' IN NATURAL LANGUAGE MODE);AND, TEH, IN 등을 무시하고, 의미있는 단어를 찾는다.
Boolean Mode
수정자(+, -)를 사용해 전체 텍스트 검색 수행
∴ 단어 단위로 분리 & 규칙 적용
SELECT *
FROM "table명"
WHERE MATCH ("index 이름") AGAINST ('+포함하고 -포함하지않고' IN BOOLEAN MODE);논리 연산자 및 와일드 카드 옵션 제공
’사람이’, ‘사람은’, ‘사람에게’ 처럼 조사가 붙는 경우 주로 사용한다.
위 예시에서 +뒤에 포함하고 라고 적었는데, +에 붙은 내용은 포함하고, -에 붙은 내용은 포함하지 않는 데이터를 검색한다.
🛠️ 과정
✔️ Natural Language Mode를 이용해 검색
@Query(value = "SELECT * FROM users WHERE MATCH(nickname) AGAINST (:nickname IN NATURAL LANGUAGE MODE)", nativeQuery = true)
User findByNicknameOnFullTextIndexing(String nickname);Native Query를 이용해 인덱스를 적용하였다.
이번 과제의 조건은 '닉네임'이 정확히 일치하는 것에 대한 조회로 일반적인 자연어 모드로 검색
만약 부분적으로 일치하는 것까지 포함하여 찾게 된다면 Boolean Mode를 이용하면 된다.
✔️ User Entity Class에 index 적용
@Table(name = "users", indexes = @Index(name = "idx__nickname", columnList = "nickname"))
public class User extends Timestamped {
...
}indexes속성에 @Index를 이용해 nickname을 인덱스로 지정
하지만 이 방법을 사용하니 Full Text가 아닌 B+Tree로 인덱스가 생성되었다.
Entity에서 indexes속성으로는 다른 인덱스를 사용할 수 없는 것 같았다.
그렇다고 직접 콘솔에서 ALTER TABLE users ADD FULLTEXT nickname 지정을 할 수는 없었다. 만약 다른 사람과 함꼐 사용할 경우, 매번 코드를 공유해야 하는 문제가 발생할 것.
다른 방법으로는 @Column의 columnDefinition 속성을 사용하는 것이었다.
https://stackoverflow.com/questions/60826399/how-to-create-full-text-index-using-spring-data-jpa
@Column(columnDefinition = "FULLTEXT KEY idx__nickname(nickname)")
private String nickname;
하지만 columnDefinition을 사용해도 index가 지정되지 않았다. 🥲
다시 알아보니 위 링크처럼 VARCHAR와 같은 데이터 타입을 앞에 꼭 지정해줘야 인덱스로 생성이 되었다.
진짜진짜최종버전 —
@Column(columnDefinition = "VARCHAR(255) NOT NULL, FULLTEXT KEY idx__nickname(nickname)")
private String nickname;
인덱스로 지정하고 싶은 필드에 columnDefinition을 사용하여 생성할 수 있다.
직접 쿼리를 작성하지 않고, nickname을 FULLTEXT index지정에 성공

이제 이 nickname을 이용해 조회를 해보자.
💡 결과
@BeforeEach와 @AfterEach를 이용해 currentTimeMillis를 계산한 시간을 구했다.
그리고 일반적인 조회와 Full Text 인덱스를 사용한 조회를 함께 실행하여 두 시간을 구분하기로 했다.
1. 첫 번째 조회
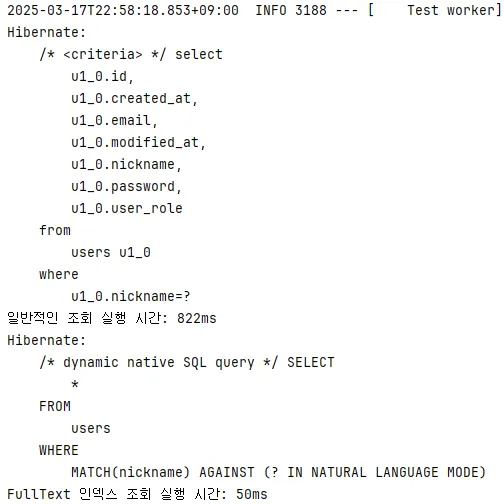
3월 17일 22시 58분 18초 실행
- 일반적인 동등 비교 연산자 사용: 822ms
- FullText 인덱스 통한 자연어 모드: 50ms
2. 두 번째 조회
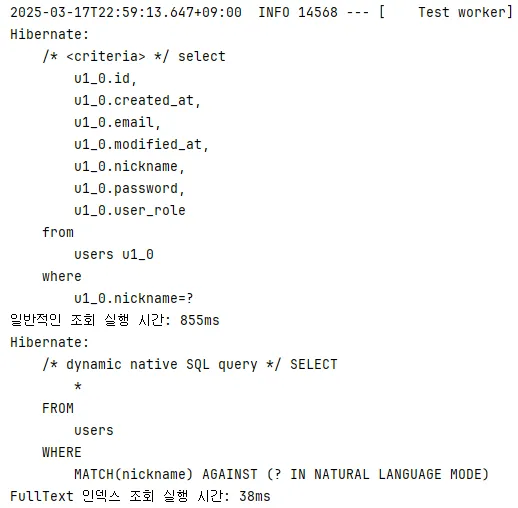
3월 17일 22시 59분 13초 실행
- 일반적인 동등 비교 연산자 사용: 855ms
- FullText 인덱스 통한 자연어 모드: 38ms
3. 세 번째 조회

3월 17일 23시 2분 5초 실행
- 일반적인 동등 비교 연산자 사용: 1055ms
- FullText 인덱스 통한 자연어 모드: 60ms
4. 네 번째 조회
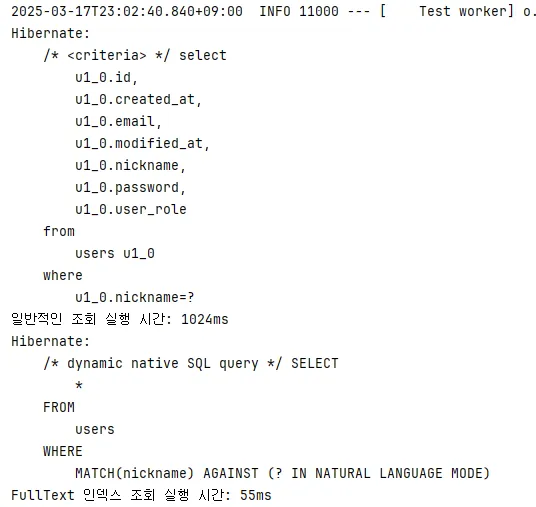
3월 17일 23시 2분 40초 실행
- 일반적인 동등 비교 연산자 사용: 1024ms
- FullText 인덱스 통한 자연어 모드: 55ms
5. 다섯 번째 조회
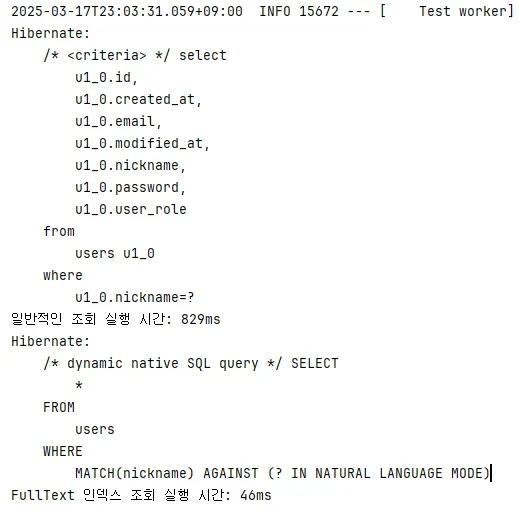
3월 17일 23시 3분 31초 실행
- 일반적인 동등 비교 연산자 사용: 829ms
- FullText 인덱스 통한 자연어 모드: 46ms
Spring이 생성해주는 ddl과 함께 보면서 그 실행 시간을 비교하며 총 5번 실행하였다.
두 방법은 조회 시간이 약 18.4배가 차이나는 걸 볼 수 있다.
🔥 트러블 슈팅 - NPE 발생
데이터를 생성해 @BeforEach에서 insert하고, @Test에서 select하는 과정 → NPE가 발생했다.
일반 조회를 할 때는 모든 데이터가 제대로 들어가고, 원하는 닉네임이 검색되어 NullPointerException이 발생하지 않았다. Index를 추가하자마자 발생하였다.
원인
MATCH .. AGAINST는 인덱싱이 이루어지지 않으면 NULL을 반환한다. InnoDB에서 FULLTEXT인덱스를 자동 갱신하지 않는다. → 인덱스 정리 필요
해결
OPTIMIZE TABLE을 실행해 PK순서대로 인덱스를 재배치한다.
OPIMIZE TABLE을 실행하면 저장소를 재구성한다.
성능을 최적화하기 위해 사용하며, 대량의 데이터를 추가하거나 삭제하는 등 큰 변화가 있을 때 주로 사용한다.
지난 번에 생성한 100만 건의 데이터를 저장한 뒤, JdbcTemplate.execute()를 이용해 직접 쿼리를 실행하였다.
@Autowired
private JdbcTemplate jdbcTemplate;
@BeforeEach
void 유저_데이터_생성(){
....
userRepository.bulkInsert(users, 10000);
userRepository.save(new User("email@email.com", "password123!", UserRole.ROLE_USER, "nickname"));
jdbcTemplate.execute("OPTIMIZE TABLES users");
}
대량의 데이터를 저장하고, 인덱스를 정리한 뒤에 조회를 하면 NPE가 뜨지 않고 조회에 성공한다.
references
https://dingdingmin-back-end-developer.tistory.com/entry/Spring-Data-JPA-6-Index-적용하기
https://stackoverflow.com/questions/60826399/how-to-create-full-text-index-using-spring-data-jpa
https://jhdatabase.tistory.com/entry/MySQL-단편화-optimizeanalyze-table-정리
'Database > JPA' 카테고리의 다른 글
| [SpringBoot/JPA] JDBC Batch Insert를 통해 대용량 데이터 저장하기 (0) | 2025.03.18 |
|---|---|
| [JPA] persist(), flush() 그리고 commit() 어떻게 DB에 반영될까? (1) | 2025.02.06 |